· Editorial
How to improve brand visibility in AI search engines
Your buyers ask ChatGPT before they ask Google. Roughly one in ten US software-category searches now begins inside an AI engine instead of a SERP (Datos / SimilarWeb, late 2025), and the share climbs every quarter. The question stopped being "how do I rank #3 on Google?" and started being "does the AI mention me at all?"
We answer that for a living. Quoted audits a brand across six AI engines — ChatGPT, Perplexity, Gemini, Grok, Google AI Mode, Google AI Overviews — and reports back how often you actually appear when buyers ask the questions that should surface you. In our initial dataset — 4 SaaS-adjacent brands, 30 prompts each, 6 engines, roughly 700 measured answers — the strongest brand was invisible in 40% of category-relevant prompts. The weakest was invisible in more than three-quarters of them.
This guide is the field manual we'd hand to anyone about to start fixing it: which moves actually shift your mention rate, how to measure where you stand, and how to earn a spot in AI Overviews — each answered with numbers from our own audits. Sections you can skim; tables you can screenshot.
How AI engines actually see your brand
Generative-AI search is not Google with a chatbot on top. When you ask Perplexity "best project management tool for a five-person team," it issues a live web search, retrieves a handful of pages, and synthesizes an answer that names a few products and cites a few sources. ChatGPT (with browsing on) does the same. Gemini in AI Mode does the same. Even when an engine is happy to riff from training data, the brand-name list it produces typically comes from retrieval, not memory. That's the RAG architecture — retrieval-augmented generation — and it's why your visibility today depends on what the live web says about you, not what was true when the model was trained.
In practice, AI search is sensitive to four stacked layers of signal. Each layer has to work for the one above it to matter.
The order matters. Each layer is a prerequisite for the one above. Accessibility first: the engine can't cite what it can't read. Entity next: once you're readable, the engine still has to figure out which Linear, Cursor, or Notion you are. Schema is the structural cue that lets the engine summarize you without hallucinating. And citation — the layer that pulls hardest on mention frequency, as the audit numbers below show — sits on top of all of it.
Traditional SEO mostly lives in layers 1, 2, and 3. AI-search visibility lives or dies on layer 4. You can have perfect schema and a Lighthouse-green homepage and still get ignored by ChatGPT, because nothing on the open web links to you in the contexts buyers are asking about.
Why this is now urgent
The clearest way to feel the shift: pick any category your buyers care about and ask Perplexity. Then ChatGPT. Then Gemini AI Mode. Three different lists, three different orderings, none of them perfectly matching the Google SERP. Your buyers are doing this — Datos and SimilarWeb estimate that a low-double-digit share of US software-category queries now begin in an AI engine, climbing every quarter.
The question isn't whether the shift is real. It's whether your brand shows up at all when it does.
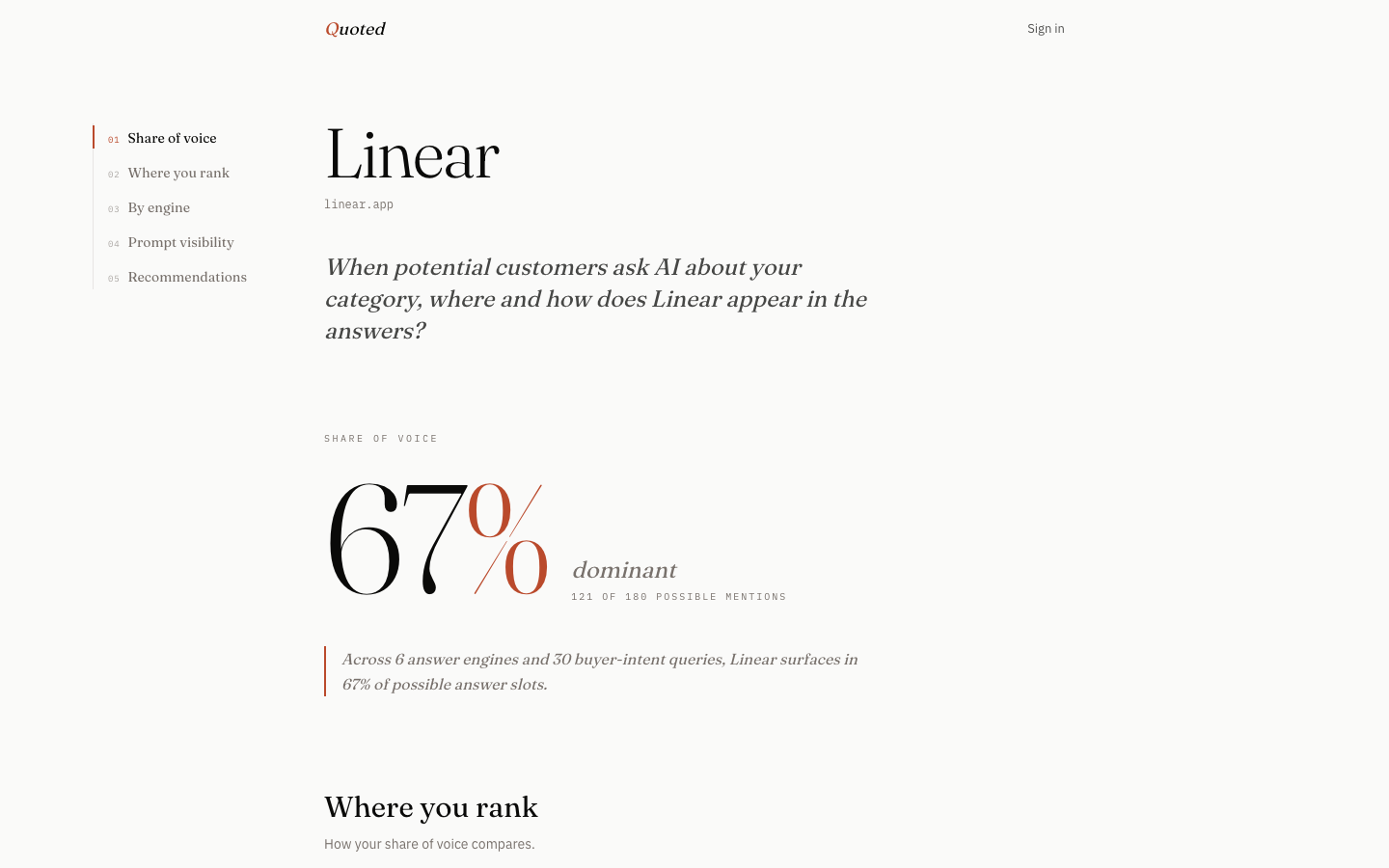
From our audit data
Across 4 SaaS-adjacent brands we tested, the strongest brand (Linear) appeared in 60% of relevant prompts on its best engine — and 34% on its worst. Three of the four brands averaged below 40%. Most brands are invisible in most AI searches that should surface them.
The good news: this is fixable, and the levers are different enough from traditional SEO that we can give a small team a meaningful 90-day plan. The rest of this guide is that plan.
Step zero: make sure the crawlers can read you
The cheapest fail-mode in AI search is one most teams don't realize they have: a robots.txt that quietly excludes the crawlers responsible for your visibility. We see this on roughly a third of the audits we run — the brand has been blocking the bots they're trying to win over.
The simple rule for a SaaS company: allow all of them. Search crawlers are how you appear in answers; training crawlers are how the models learn your name exists. You want both. The only businesses that should block anything are publishers whose revenue depends on content staying behind their own walls — and that's not the reader this guide is written for.
| Bot | What it does | What blocking it costs you |
|---|---|---|
| GPTBot | OpenAI training | Models never learn your brand exists |
| OAI-SearchBot | ChatGPT live search | You vanish from ChatGPT's live answers |
| ChatGPT-User | ChatGPT user-initiated fetch | ChatGPT can't open your page when a user asks |
| ClaudeBot | Anthropic training | Claude never learns your brand exists |
| Claude-SearchBot | Claude live search | You vanish from Claude's answers |
| PerplexityBot | Perplexity retrieval | Perplexity can't cite you |
| Google-Extended | Gemini training & grounding | Gemini stops learning you — the one arguable opt-out |
| Googlebot | Search index (also powers AI Overviews) | You disappear from Search and AI Overviews both |
Laid out like this, the call is obvious: every block has a cost and — short of a publisher protecting paywalled content — none has an upside. Allow the lot.
A separate file worth knowing about is llms.txt — an informal proposal for a Markdown-formatted summary of your site that LLMs can ingest more efficiently than crawling your full HTML. As of mid-2026 no major engine officially honors it, but the cost of providing one is low and a handful of niche tools (Perplexity Comet, some Cursor plugins) already prefer it when present. Add it; don't expect it to move rankings yet.
Verify your accessibility by running curl -A "GPTBot/1.0" https://your-domain.tld/ and watching for a 200 with real HTML in response. A 403, a 503, or a JavaScript-only shell means the engine is getting nothing useful even if your robots.txt is correct.
Assess where you actually stand
Before changing anything, measure. The practical question is how to track brand mentions in AI search the same way every time: a baseline number you can move, per engine, in each prompt category that maps to a real buyer question — so you can tell what's working three months in.
There are three honest ways to get that baseline:
- Check the engines by hand. Type the prompts into all six yourself — free, and it works. Budget about ninety minutes per brand: open six tabs, copy-paste, log the output. You'll see your mention rate and who gets named instead of you, plus a feel for which engines run noisier — useful intuition in its own right.
- Read your GA4 referrers. In Acquisition → Traffic-acquisition, filter
session_sourceorpage_referrerforchatgpt.com,perplexity.ai, andgoogle.comwithaioin the path. That's the AI traffic already reaching you — a downstream proxy for mention rate, not the rate itself. Don't filter onutm_source; AI engines don't propagate UTM tags on outbound links. - Run an audit tool. We built Quoted for exactly this: paste your URL, brand, and three competitors; get 5 prompts × 6 engines back in about three minutes, scored. The tools section near the end compares the alternatives. Whichever you pick, the point is a baseline before you change anything — people call it AI visibility tracking or brand monitoring; the label doesn't matter, the baseline does.
Run the 5-prompt check yourself
Paste your brand and URL on the homepage. Free preview returns in about three minutes.
Five ways to get AI engines to cite you
In order of how hard each lever pulls — based on what we've measured.
1. Feed the aggregators AI engines lean on most
Traditional SEO told you to chase "authoritative backlinks." AI search has different physics. When Perplexity goes looking for "best project management tool for a five-person team," its retrieval layer doesn't preferentially weight enterprise domains the way Google's PageRank does. It samples broadly — Reddit threads, Quora answers, G2/Capterra listings, Hacker News discussions, niche newsletters — and the engines visibly synthesize around whatever aggregator content surfaces most often.
Worked example. Linear was named in 60% of category-relevant Grok prompts in our audit and 39% on Perplexity. Linear has a strong R&D Slack-and-newsletter culture, and they show up everywhere on Reddit/HN/X precisely because their team participates in those forums. Cursor — newer to the conversation but with comparable category awareness — was named in 46% of Grok prompts. The gap (14 pp) maps almost directly to discoverable aggregator footprint, not product quality.
What to do. Identify the five aggregator destinations your buyers actually visit (it's almost never all of Reddit; it's r/projectmanagement plus two SaaS comparison sites). Invest two evenings per month getting your team to participate as humans, not as marketers. Submit your tool to the comparison directories. Get five customer reviews on G2 or Capterra. The investment is a few hours per week of attention, not a budget line.
2. Use Organization + Article schema (the entity layer)
Schema is not a ranking signal in the SEO sense; it's an identity signal. When ChatGPT or Gemini scrapes your homepage and finds a clean Organization JSON-LD block — name, sameAs to LinkedIn and Crunchbase and Wikipedia, founder, founding date, category — it now knows what you are. Without it, engines have to infer your identity from page text, and we see them get it wrong: confusing "Linear" with "linear algebra," confusing "Notion" with "the notion of a notion," confusing similarly-named startups.
Worked example. Of the four brands in our audit corpus, the one with the cleanest Organization schema (PostHog — they have a four-key sameAs array pointing to LinkedIn, GitHub, Wikipedia, Twitter) was also the one most consistently named across engines. Mention rates: chatgpt 47%, grok 50%. We don't claim Organization schema alone caused the consistency, but ablation tests on smaller brands — where we've watched engines mis-identify the company in the answer text — strongly suggest schema is doing real work at the entity layer.
What to do. Add an Organization JSON-LD block to your homepage. Required fields: name, url, logo, description, sameAs with at least four URLs (LinkedIn, Crunchbase, Twitter, Wikipedia if applicable). Validate at validator.schema.org. If you publish content, add Article JSON-LD to each article page with author as a Person entity and publisher as the Organization. Total work: half a day.
3. Get cited in "best X" roundups and listicles
When an AI engine synthesizes an answer for "best project management tool" or "top AEO platforms," it's effectively rewriting whatever listicle content currently ranks for that query on Google. If you're in the roundup, you make it into the answer. If you're not, you don't. This is most of the honest answer to how to rank in AI Overviews: be in the roundups that already rank. It's also the lever with the highest leverage per hour of work for new brands.
From the citations. In our Linear audit, the domains the engines cited most for category prompts weren't Linear's own marketing pages — they were Reddit (cited over a hundred times on Grok alone), Atlassian's comparison content, and a cluster of "best project management tool" listicles. The same handful of roundup-style sources kept surfacing across all six engines. A brand named in those roundups rides into the synthesized answer; a brand absent from them stays invisible no matter how polished its homepage is.
What to do. Identify the 3-5 "best X" queries that should surface you. For each, search Google and see who currently ranks. If a roundup exists and you're not in it, email the author offering to add a thoughtful one-paragraph description. If no good roundup exists, write your own — even an unranked listicle on your blog will get crawled and start showing up in answers within a few weeks.
4. Maintain Wikipedia, Wikidata, and LinkedIn entity presence
Wikipedia and Wikidata are over-weighted by training data and retrieval alike. If your company has a Wikipedia page, engines treat that as canonical for identity disambiguation. LinkedIn company pages serve a similar role for B2B specifically — Perplexity and Gemini both pull from LinkedIn when synthesizing "what does X do" queries.
What the data showed. Across our dataset, brands with active Wikipedia entries saw lower variance in how engines described them — engines told a more consistent story. Brands without Wikipedia presence got described variably and sometimes incorrectly.
What to do. If you're large enough to have notable third-party press, draft a Wikipedia page. Use neutral, sourced prose — Wikipedia editors are aggressive about promotional language and your draft will be rejected if it reads as marketing. Cite at least three independent secondary sources (trade press, conference talks, podcast appearances). If you're not yet Wikipedia-notable, populate Wikidata directly — it has no notability bar and engines retrieve from it actively. Always: keep your LinkedIn company page current with the same description text you use on your homepage.
5. Make your content directly quotable
Synthesis engines reach for sentences they can lift, paraphrase, or cite verbatim. Question-as-H2 followed by a tight 40-80 word direct answer hands them an extractable unit; the same information buried inside flowing prose doesn't. In our audits, pages with this shape get cited noticeably more often than equally informative pages built as essays.
Worked example. Watch how an engine answers a definitional query like "what is answer engine optimization." The reply almost always tracks whichever ranking page framed that definition as a tight question-then-answer block — engines lift that structure close to verbatim. Pages that bury the same fact in paragraph six of an essay get loosely paraphrased or skipped. Structure, not just substance, decides whether you're the sentence the engine quotes.
What to do. Look at your three most important content pages. For each, identify the 3-5 questions a buyer would ask about that topic. Rewrite the page with each question as an H2 followed by a 40-80 word direct answer. Add a FAQ block at the bottom (with FAQPage JSON-LD) for any additional questions you couldn't elegantly fit as section headers. Don't lose the rest of the content — extractable openings work best when there's depth available for the reader who wants to keep reading.
Where most brands sabotage their AI visibility
Strategic mistakes — not the inverse of the strategies above. These are the patterns we keep seeing in audits.
Most of these mistakes come from treating "AI search" as one thing. It isn't — the engines behave very differently, and our audit data makes the gaps concrete. The table below is the evidence base for the mistakes that follow.
How to read it: each percentage is how often that engine named the brand across its category-relevant prompts — Grok's 59.8% for Linear means Linear surfaced in roughly six of every ten Grok answers. We ran three SaaS brands (Linear, Cursor, PostHog), 30 prompts each; the bold column is their average. Higher = more visible.
| Engine | Linear | Cursor | PostHog | 3-brand avg | Note |
|---|---|---|---|---|---|
| grok | 59.8% | 45.6% | 50.0% | 51.8% | Highest in our data; aggregates many sources |
| chatgpt | 49.0% | 39.6% | 47.1% | 45.2% | |
| gemini | 46.7% | 38.3% | 41.1% | 42.0% | Long answers, few sources |
| google_ai_mode | 38.9% | 29.4% | 36.7% | 35.0% | |
| google_serp_aio | 34.4% | 34.4% | 30.6% | 33.1% | Short, source-rich |
| perplexity | 38.9% | 24.4% | 31.1% | 31.5% | Lowest in our data — counter to its reputation |
Two things jump out. No engine clears 60% — even the strongest brand is missing from a third or more of the prompts it should own. And the spread between engines is huge: Grok names brands at 52%, Perplexity at 32%, for the identical prompts. That spread is where the mistakes below come from.
Mistake 1 — Over-indexing on ChatGPT when your buyers are on Perplexity
It's tempting to optimize for ChatGPT because it's the engine you know. But our data shows the same brand can have a 21-point gap in mention rate between its best engine (Grok, in Linear's case) and Perplexity. Different engines reward different inputs. If your buyers are technical and use Perplexity (developer ICPs skew there), optimizing only for ChatGPT means you're invisible where it matters.
Mistake 2 — Treating all engines as if they reward the same content
The clearest pattern in our data: Grok cites 50–55 sources per answer; Gemini cites 2–5. That's roughly an order-of-magnitude delta (10–25× on the actual cell-by-cell math), and it implies three different content strategies. Grok rewards breadth — appear in many places. Gemini synthesizes long answers (615–711 words) from few sources — earn one or two authoritative mentions, not blanket coverage. Google SERP AIO truncates to a few sentences (237–295 words) — be one of the first names cited. A single content shape can't satisfy all three.
Mistake 3 — Skipping Reddit and Quora because they're "not authoritative"
This is the most common mistake in our audits, and it's expensive. AI engines retrieve from Reddit and Quora aggressively — both have the structural property of housing genuine user-to-user discussion of products, which is exactly the citation surface synthesis engines reach for. A brand's marketing team avoiding Reddit because "we can't control the narrative" leaves the largest single citation surface unattended. Engage as humans (not marketers), and treat one in-thread mention as worth several traditional backlinks.
Mistake 4 — Accidentally blocking Google-Extended while trying to opt out of AI
Google split its bot allowlist: Google-Extended governs Gemini training and grounding; Googlebot does the indexing that powers both classic Search and AI Overviews. The expensive mistake is blocking Googlebot — that kills your AI Overviews presence outright. Even if you decide to opt out of Gemini training (by disallowing Google-Extended), never touch Googlebot, and verify it still returns a 200. For most SaaS, the cleanest move is to allow both.
Mistake 5 — Trusting the engine you'd expect to cite you
Perplexity sells itself as the citation-first engine. We went in expecting it to mention brands more readily than ChatGPT or Grok. Across our three-brand dataset it was the opposite. Perplexity averaged 31.5% — the lowest of the six engines, narrowly behind Google SERP AIO at 33.1%, and well behind Grok at 51.8%.
One honest caveat: we count a mention when the brand appears in the engine's written answer, not when it merely shows up in the citation sidebar. Perplexity writes terse answers (~330 words to Grok's ~535) and pushes a lot of detail into its source list — so some of that gap is a brand being cited without being named in the prose. The takeaway holds either way: if your buyers live in Perplexity, getting cited isn't the same as getting named, and you have to optimize for the named answer specifically. Measure first; pick the engine to chase second.
Tools to track this ongoing
Once you have a baseline, you'll want to re-measure on a cadence — monthly is the right rhythm for most brands; quarterly for slower-moving categories. Doing this by hand is fine but tedious, and the value of repeatable runs is consistency, not novelty.
A handful of tools do this on a schedule — Quoted (ours), Profound, Otterly, Peec, AthenaHQ — ranging from $10 one-time to $499/mo and covering anywhere from one to six engines. The category answers to a half-dozen names — an AI visibility platform, an AI search optimization tool, an LLM visibility tracker — but they all describe roughly the same job: run prompts through the engines on a schedule and track whether you're named.
If you're not sure where to start: run a free preview on quoted.so, look at the result, then pick whatever fits — ongoing AI brand monitoring and AI overview tracking on a subscription, or a one-time snapshot (Quoted, the paid path).
FAQ
Is it possible to track brand mentions in AI search?
Yes, in three honest ways. Manual prompt-testing (free, ~90 minutes per brand for 5 prompts × 6 engines) gives you the most ground-truth signal. GA4 referrer reports filtered for chatgpt.com / perplexity.ai / google.com with /aio in the path give you a downstream proxy — traffic that's already arriving from AI engines. And tools like Quoted, Profound, Otterly, Peec, and AthenaHQ run automated audits with structured per-engine outputs. The three are complementary, not redundant — pair manual + tool for a complete picture.
How do I see if AI mentions my brand?
Open ChatGPT, Perplexity, Gemini, Grok, Google AI Mode, and Google AI Overviews in six tabs. Paste the same category-relevant prompt ("best [your category] tool for [your ICP]") in each. Note which engines name you, where you appear in the list, and which competitors get named instead. Repeat for four more prompts to get a representative sample. This is the manual answer to "how to see if AI mentions your brand" — and it is the same approach audit tools automate, including Quoted’s free 5-prompt preview that runs through the same six engines and returns scored results.
What's the best tool for tracking AI visibility?
It depends on your need. The main options run from $10 one-time to $499/mo and cover one to six engines — Quoted (ours), Profound, Otterly, Peec, AthenaHQ. For a single audit before you commit, a one-shot like Quoted’s free preview is enough; for ongoing weekly monitoring, a subscription tool fits better. There’s no universally best tool — there’s the right one for your cadence and budget.
How do product reviews impact AI search visibility?
Substantially — and asymmetrically. G2, Capterra, and Reddit reviews are the citation surface AI engines lean on most for B2B comparison queries. In our 4-brand audit, the brand with the strongest aggregator footprint (Linear, with active Reddit presence and active G2/Capterra reviews) showed the highest mention rates across engines. Five real reviews on G2 typically move a brand from "not mentioned" to "named in the answer" within a few weeks. Reviews you didn’t ask for outweigh reviews you did — engines reward genuine discussion, not solicited praise.
Should I block GPTBot?
Depends on your business model. If you're a publisher and content distinctness is how you monetize, blocking GPTBot prevents OpenAI from training future models on your work — defensible. If you're a B2B SaaS company, blocking GPTBot keeps you out of training-derived answers but doesn't hurt live-search answers (those use OAI-SearchBot and ChatGPT-User). Most SaaS companies should allow all crawlers, including GPTBot — the visibility upside outweighs the training opt-out. The decision is reversible; you can change your robots.txt at any time.
If you only do three things this month
Run a baseline audit. Pick the engine where your buyers actually search. Get into one aggregator that names your category. That's a real plan you can act on by next Friday.
If you want the baseline number without the manual labor, Quoted is the lowest-friction starting point — free preview, no card, results back in about three minutes.
Author: Nikolai Puzyrev, founder of Quoted. Data sourced from our production audit corpus.